

Usually, at the preparatory stages of project developers think of the project skeleton to avoid a lot of mistakes and reworks in the future.
Brief description of arc.js architecture
What is the arc.js approach? Firstly, it is atom approach to the design of the components.
Atoms are the smallest components that are responsible for one specific function. For example, button with label, text field, spinner, etc.
Molecule is the component that includes several Atom components, but it is not the fullest one. A molecule may be modal window or button with an icon inside.
Organisms are usually components responsible for the specific function of the application. For example, registration form, table with data and filters.
Honestly, sometimes it is not so easy to divide components into these three groups, but with arc.js you can easily transfer these components between the groups.
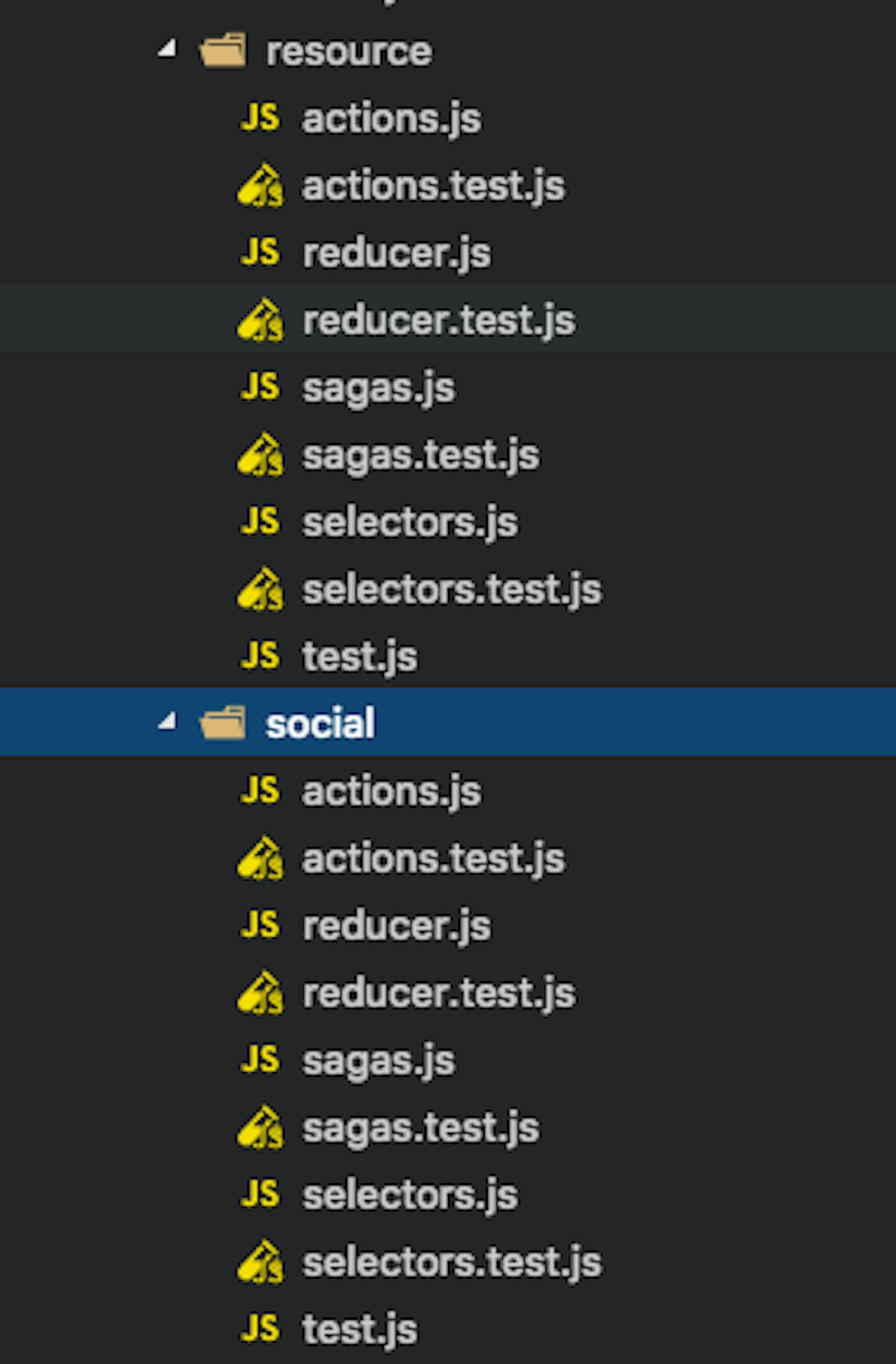
The structure of the skeleton is the following:
Components folder is responsible for the storage of all the components (atoms, molecules, organisms). The folder also includes pages, templates, themes and, in particular, contains the main entry of the project — index.js and App.js. In this folder, dumb components are placed as well.
Dumb component is a component that has no business logic, operating only with actions and modifying its simplest state (if necessary) to change its appearance.
Containers is a folder that contains smart components that are responsible for the state management and actions dispatching.
Smart component dispatches actions, gets action results from the state and maps statuses of errors or data loading. In simple words, smart components contain the meaningful information that is not available for dumb component. Smart component covers dumb one and endows additional skills to it according to the “decorator” pattern principle.
Services/api folder has necessary methods to work with REST API, i.e. in this case, the simplest implementation of error handling and the usage of “fetch” to make requests to the server.
Services/validation folder contains all necessary validators to check the correctness of the data (may be used together with redux-form)
Store/entities folder has introduction of schemes, middleware for processing of api data and their transformation into the entity, that is convenient for the further usage. This is implemented through normalizr (you can read about this in details here: https://github.com/paularmstrong/normalizr). It is very cool mechanism for two-side mapping, especially if it is necessary to change the way how the data is presented for display. Herewith, it sends the data to the server as it was before. Irreplaceable tool.
Store/resource folder contains everything that is necessary to interact with api through redux-saga.

Advantages of arc.js architecture
- As a layer between business logic and display of data, redux-saga is used. This allows dividing the logic into modules. For example, authorization via social media and requests to api sources may work absolutely independent. They know nothing about each other. Such division allows keeping actions, sags, reducers and selectors separately for each module.
- Simplifying the mapping and transformation of data from API.

- Usage of normalizr data schemes.

scheme title = resource title
- Implementation of resource approach and Flat REST. Thus, in fact, we use the same code to interact with different resources without the duplicating (tracking of statuses and data works separately!).
Resource is a disposable url, that does not have any nestings and definitely tells about the undertaken action. For example, in Flat REST it is necessary to make /posts?userId=1 (here posts is a resource) request for data filtering to get user’s posts. While in simple REST the request is usually done in the following way: /users/1/posts (this may have multiple nestings like /users/1/posts/1/comments, etc.).
- Since a resource is always a plural noun (posts, users, comments, etc.), looking at the resource title and understand what you will get as the result!

The example of sag generator to get the array of data through resource title or aliases.

As the endpoint, we mention resource title, useful load — as data, additional parameters and the value of headers (ex: authorization token — as settings).
- The usage of selectors to choose the data from state hides the details of selection (since there may be multiple nesting in the object of data state). By this, the duplication of the code decreases as well. The approach allows changing the methods of data requesting through selector in such a way that changes will be applied only for certain part of the code. For example, instead of state.resource.detail we will use fromResource.getDetail(state), and inside of the method state.resource.detail will be hidden.
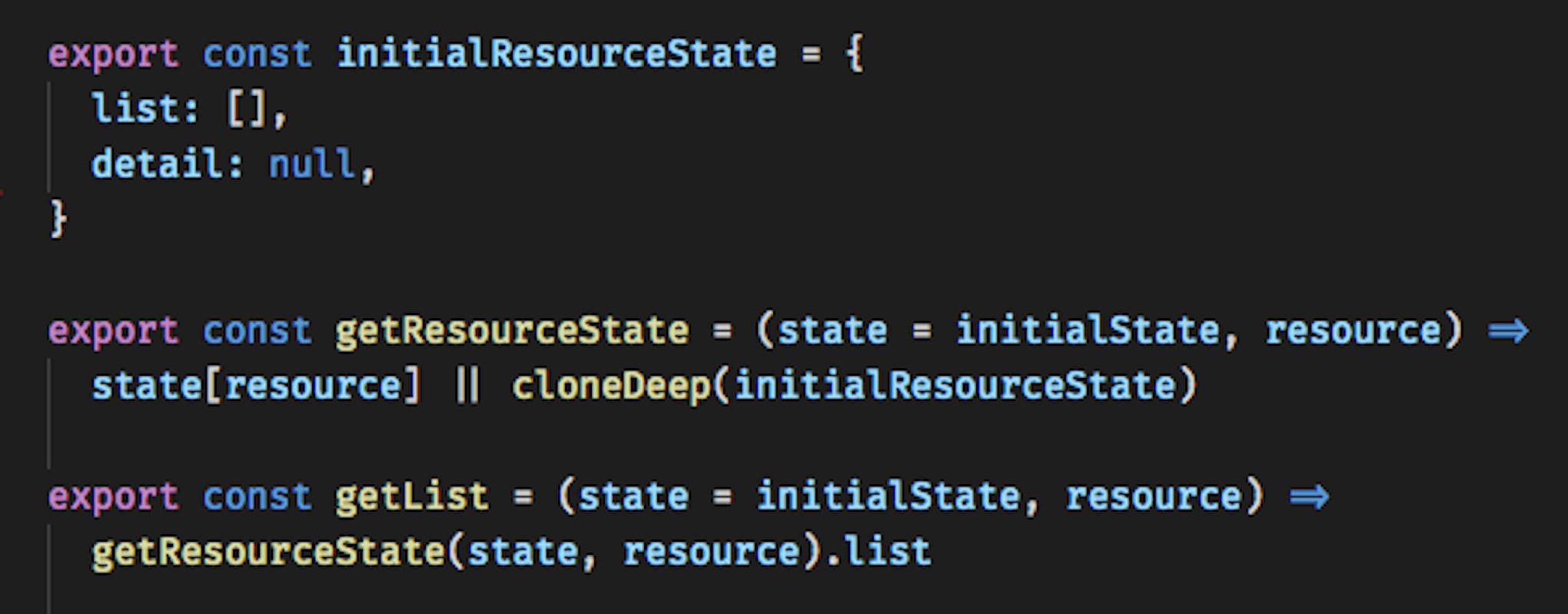
This is how the selectors look like, where resource is posts, users or comments
- The convenience of testing and writing tests for the components! This is a very important feature since we can run tests for a single component and it is not necessary to look for the test in the whole list since the test is placed in the folder with the component. It increases the portability and self-sufficiency of the component. If you run yarn test:watch command, a worker will clearly identify the list of test to be run since they are in the same folder as component code. You can also easily edit or add tests.

Here is the view of the component folder with tests
- Mapping of selectors, sags, components, containers is automatic that allows not to think whether you have included “import” to index.js or not. You simply use the following format of syntax:
import { SomeComponent } from ‘components’
or
import { fromResource } from ‘store/selectors’
Such approach allows transferring components between different folders like components/atoms or components/molecules. Herewith, you may not care that something will be broken since using relative routes like ‘../molecules/SomeComponent’ the component location is strictly defined. Therefore, with the transfer of the component, you have to change the link to the component (if we decided that it is not a molecule, but an atom or an organism). Due to this, it is impossible to create cyclical links when one module refers to the other one that refers to another module referring to the first one. Thus, it is necessary to think and use DI principle to divide dependencies and get them as parameters.

This is an example of module from auth folder that requires specifying a component to display “Signing in” state in authorization process to show the user what is going on if the process will take more time than assumed.
The solution for this is obvious: since we cannot import a component — import { SigningInPage } from ‘components’, we can use DI and specify the parameter to pass component into the function creating the auth wrapper. As a result, we use a function in the following way:

Thus, we do not have any cyclical links and we can specify different Loading pages for wrapped components of the pages. Herewith, components or auth wrappers are not aware of specific component details and of how the wrapping works.
The example of code that joins all the components into namespace_components and containers:

Disadvantages of arc.js implementation and solutions to them
Here is important to say that disadvantages are specific to each project.
I revealed the following disadvantages from my practice:
- The absence of alias set up for the same source. Alias is required to make a request for the same source but without the data overlapping. For example, if in one of your forms you request the list of all cities and in the other form you select cities given country, there may be data conflict. To avoid this, it is necessary to add aliases. For each alias, there are specific data schemes in entities. Thus, the requests may be made to posts, but the data may be placed into the collection called social_posts (if we choose posts with “social” type), thanks to aliases. Then with selectors, we may get data from fromResource.getList(state, ‘social_posts’)

In resourceAlias “posts” are set up and in resource — “social_posts”. As a result, the requests will be made to posts, but the data will be saved into social_posts
- It is impossible to get response data separately from API titles and json data.

To solve this, we partially change method parsing server responses. In headers we write the information from titles and data from response body is written into json attribute.
- Inability to go over the component code through Ctrl+Click, using the namespace of components or containers type. Yet, I think it is not a big problem since you always can find the component by its name.
Conclusion
In conclusion, it is not always necessary to use arc.js skeleton to set up supported architecture, but the skill to notice cool features of this architecture that may significantly simplify your work is very important.
For example, the simplest solution for the check of status.ok response status and generation of exceptions in case of status.ok = false inside services/api allows to avoid the insertion of the code duplication for the check and exception generation with every revoke of API in the modules, used this call.
The usage of url = resource approach allows not to create the same code for each URL that processes server response, except the change of url, and set up of parameters in a given order. We use a generic-like approach that is beneficial in code reuse.
The usage of selectors allows hiding the branching of data in the state from the user who applies selector. Due to this we can display the same result with different data structures and by making changes only in one place.
Any skeleton definitely has to be finalized to make it satisfy all the requirements. Skeleton without any modifications is rarely used.
Putting the logic of api interactions into the redux-saga modules allows transparent response processing and setting isPending, hasFailed and other statuses. Herewith, the amount of code significantly decreases. The approach also enables usage of generators that are becoming popular now due to the simplicity of their implementation and testing.
What is more important is that the same things may be done by Saga! It allows to get different states with different resources without attachment to specific details as referring to the data works with selectors and redux-saga slide-effects. The approach is similar to the usage of interfaces in the strongly typed languages where you know what methods are represented by the interface but says nothing about their implementation. It also allows avoiding cyclical links and complicated distribution of attributes to nesting components.
Useful links





Strapi: Things to Keep in Mind Before Migrating to...
Strapi: Things to Keep in Mind Before...
Strapi: Things to Keep in Mind Before Migrating to This CMS
When it comes to CMS, the modern market has already stepped so much that the choice is becoming increasingly difficult. There are so many options for...
